A draft note about deep learning. Mostly start with what, why and how!
Architecture
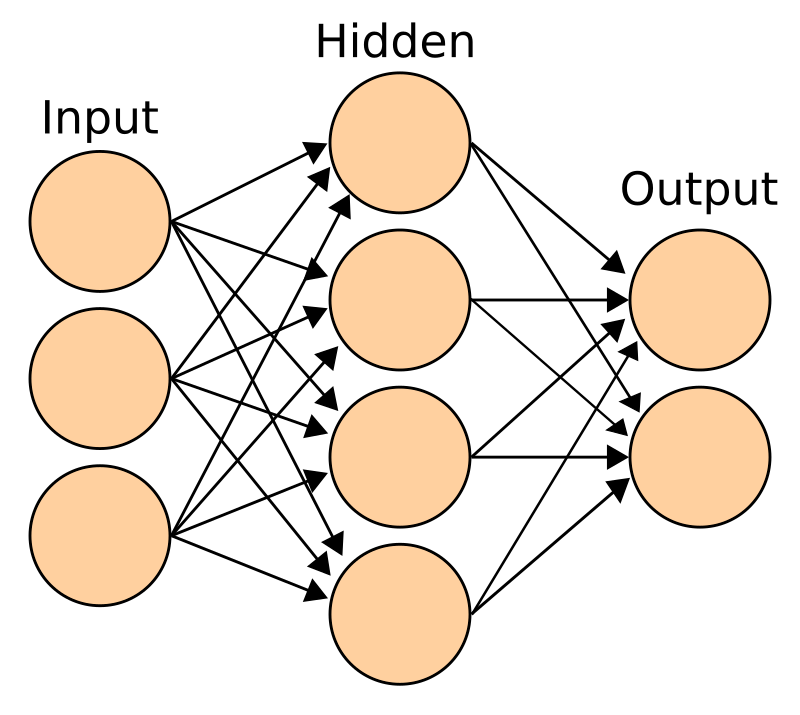
What is Dense?
Fully feed forward
Neural layer that connect to all the previous neural layer
We typical see that in layer construction
| |
CNN
What hidden layers in CNN?
- Convolutional layers
- Pooling layers
- Fully-connected layer
- Normalization layer
What is the purpose of Convolutional layers?
Extract the feature from kernel (typical the dot product)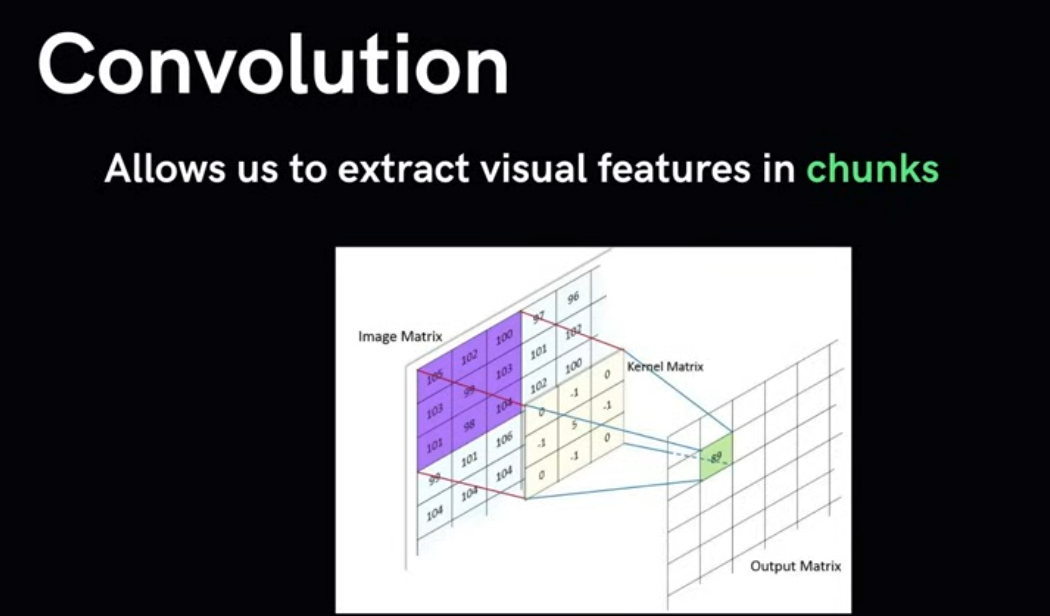
What is the purpose of Pooling layers?
Reduce the number of neurons
Use max or min for extract the value in the grid
Example flow how apply those CNN hidden layers?
And flatten
RNN overview
What is RNN?
Also feed-forward neural network but fixed size of input and output
Use for remember the past and current information to predict
How RNN keep track relationship between each feature in the sequence?
Sharing parameter give the network ability to look for a given feature everywhere in the sequence:
- Deal the variable length
- Maintain sequence order
- Keep track long term dependencies
- Share parameter across sequence
How RNN actually store the sharing parameter?
Use a feedback loop in the hidden layer (short term memory)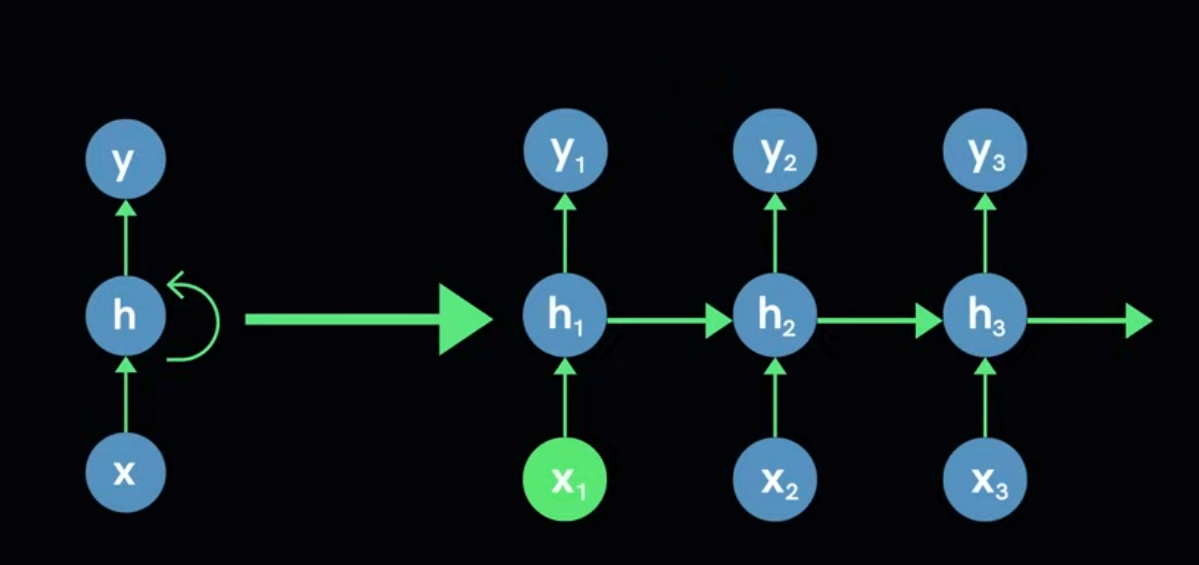
How it learn in RNN (the backpropagation)?
Backprop applier for every sequence data point
Backprop through time (BTT)
Problem of RNN?
Short term memory in RNN is due to vanish gradient decent
When we have a long sequence, we forgot a lots
Ex: we have no idea the word “it” and “was” to use due to vanish gradient => it hard to predict with just “on Tuesday”
Why it occur vanish gradient decent in long sequence when use RNN?
Backpropagation: when use calculate gradient base on previous layer
If init gradient is small => smaller until vanish
RNN
Intuitive approach
How to handle with variable input size?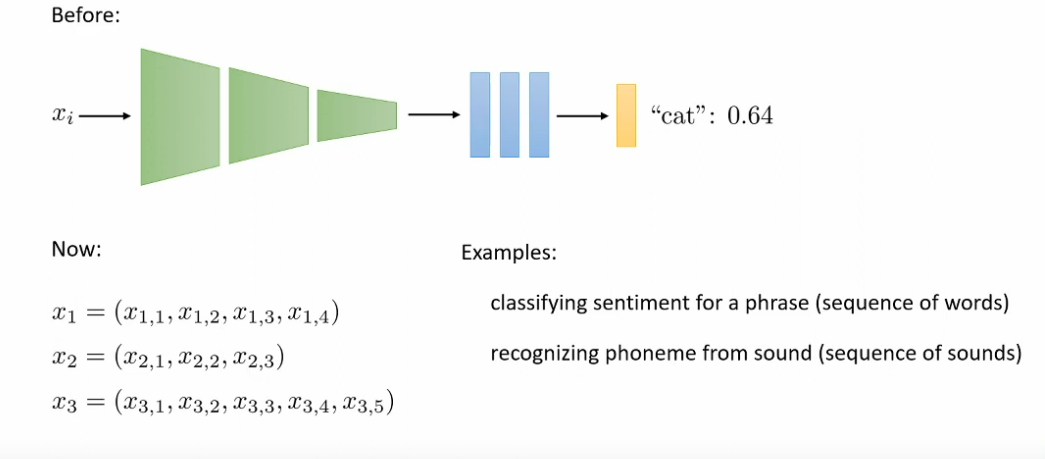
__
We can padding input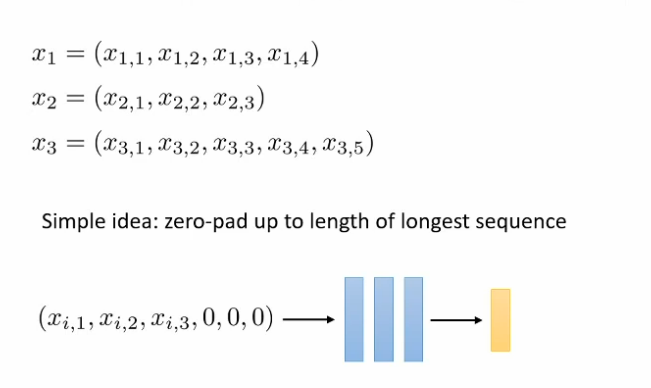
But it not work well in the length sequence
How the linear function in this RNN sequence?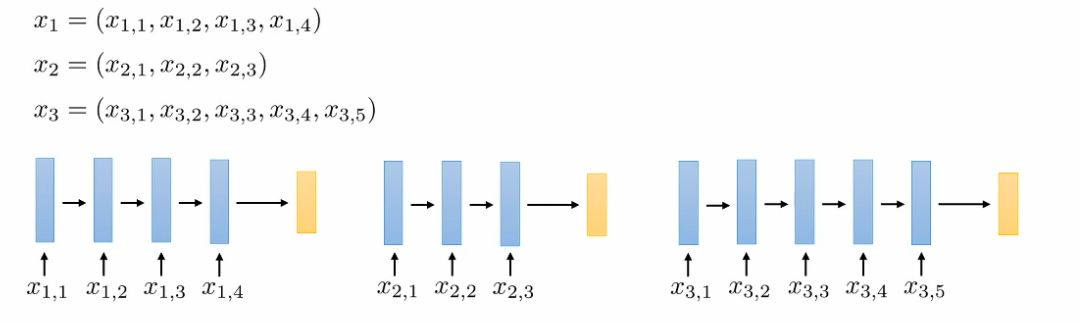
__
We could use with the input is the previous activation value ($a^{l-1}$) and the input value in sequence $x_{i,t}$
and weight and bias for each layer individual (???). and yes still go through a activation function.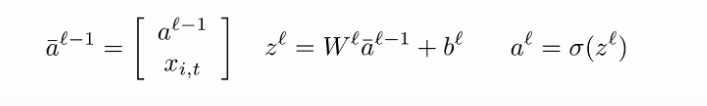
How we handle missing layer because the input size is not the same?
Padding the amount of first layer as activation value is 0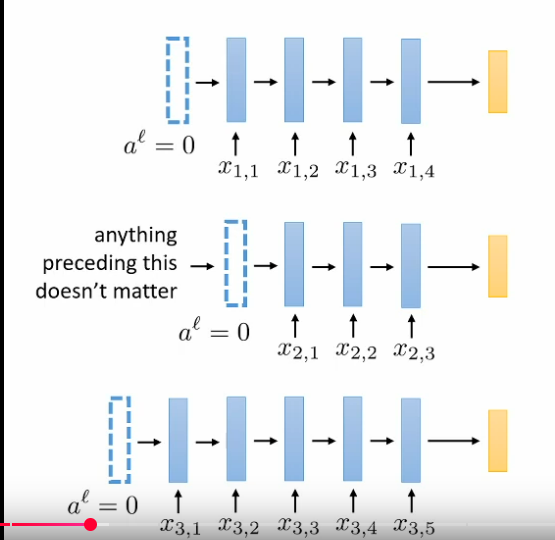
What happened when we use the weight and bias for each layer individual ($W^l$, $b^l$)?
We should share the weight matrix and bias for the whole sequence to avoid too many weight matrix
We can have many layer as we want in RNN because not require more param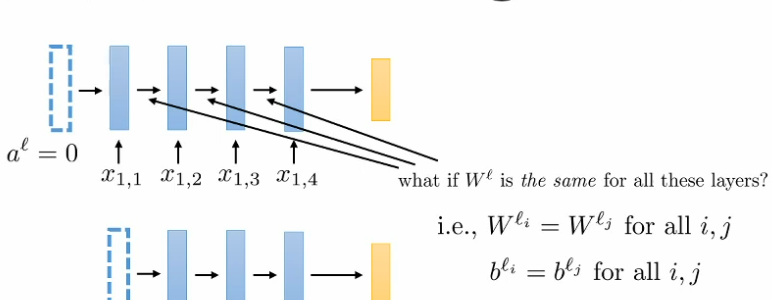
Problem with RNN?
- Need to process sequence make it impossible not parallel
- Multiply many many number again and again make vanish gradient or exploding gradient

What problem with vanilla RNN when predict the whole sentence without knowledge about previous result timestep?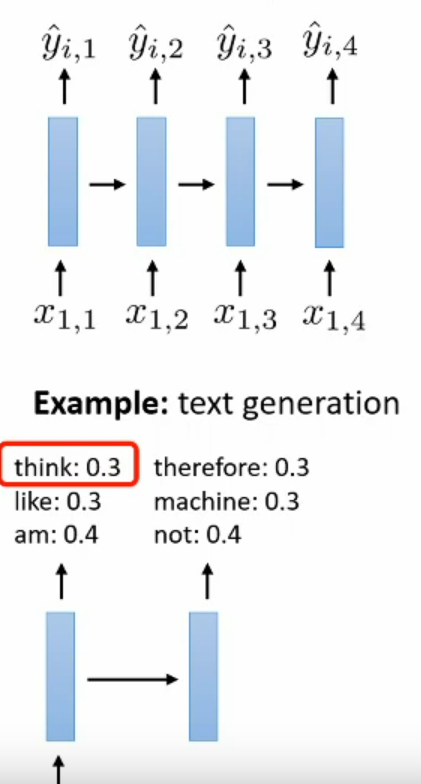
__
If not base on previous input the result sentence output can be pointless because no connection in sentence
The future output must base on the past output for predict next input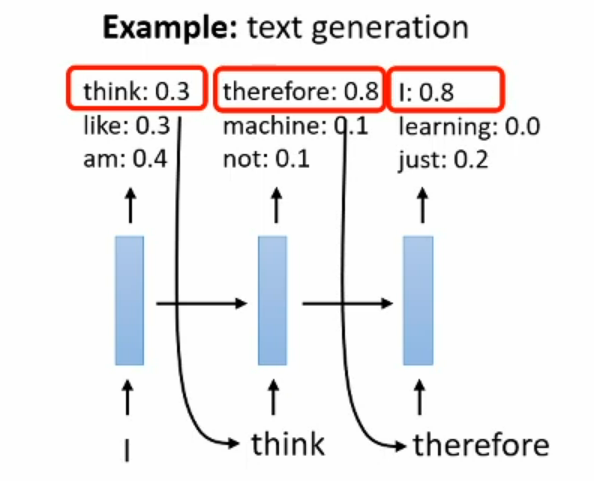
What problem that distributional shift describe?
How the heck we know predict right sentence when the first token is “I”
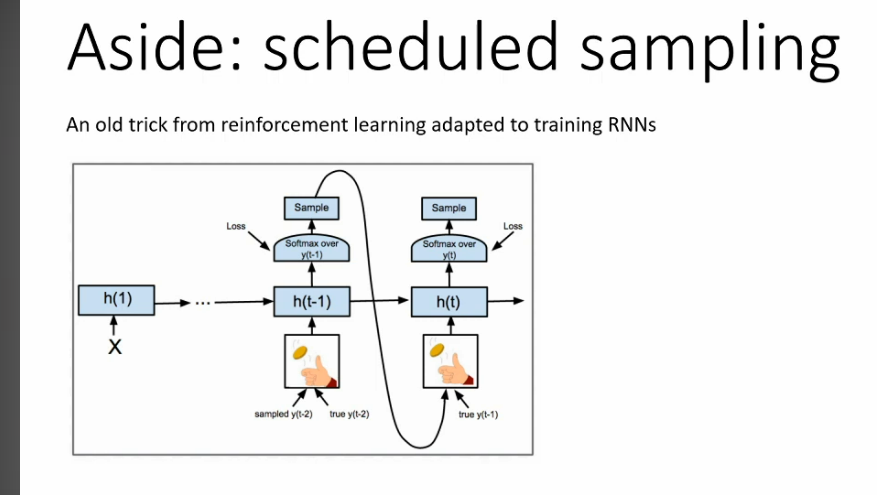
Schedule sampling
Schedule Sampling Analogy: Learning to Play a Musical Piece
Imagine you are a music student (the model) learning to play a complex piece on the piano.
1. Traditional Training (Teacher Forcing):
- Your music teacher (ground truth) is sitting right next to you.
- Every time you play a note, even if you make a mistake, the teacher immediately tells you the correct next note to play. They guide your fingers precisely.
- The problem: You’re not really learning to recover from your mistakes. If the teacher suddenly vanished, and you hit a wrong note, you’d likely get completely lost because you’ve never practiced figuring out the correct sequence after an error. This is exposure bias. You’re exposed only to perfect sequences.
2. Schedule Sampling (The Smart Way to Learn):
Now, your teacher uses a new method: - Early in your practice (high probability of teacher guidance): The teacher still helps you a lot. Maybe 90% of the time, they tell you the correct next note even if you messed up. This helps you learn the basic melody.
- Gradually, as you get better (decreasing probability of teacher guidance): The teacher starts to withdraw their help.
- Sometimes (say, 20% of the time), they’ll let you play your own wrong note and then make you figure out the next note based on your own incorrect position.
- They might still correct you on subsequent notes, but you’re getting practice navigating from a “bad state.”
- The percentage of times they force you to play your own note increases.
- Late in your practice (low probability of teacher guidance): You’re mostly playing the piece on your own. If you hit a wrong note, you have to try to recover and play the correct next note from that mistaken position.
The “Why” it’s Needed (and why Schedule Sampling is good):
By gradually forcing you to play from your own (potentially wrong) previous notes, you learn:
- Resilience: You get better at recovering when you make a mistake.
- Robustness: Your performance doesn’t fall apart completely just because of one small error.
- Real-world Readiness: When you perform the piece by yourself (inference), you’re prepared to handle any missteps, because you’ve practiced playing without constant perfect guidance.
In summary: Schedule sampling is like a smart teacher who gradually reduces their direct help, forcing the student to learn from and adapt to their own errors, making them a much more robust and independent performer.

Seq2Seq
Use this architecture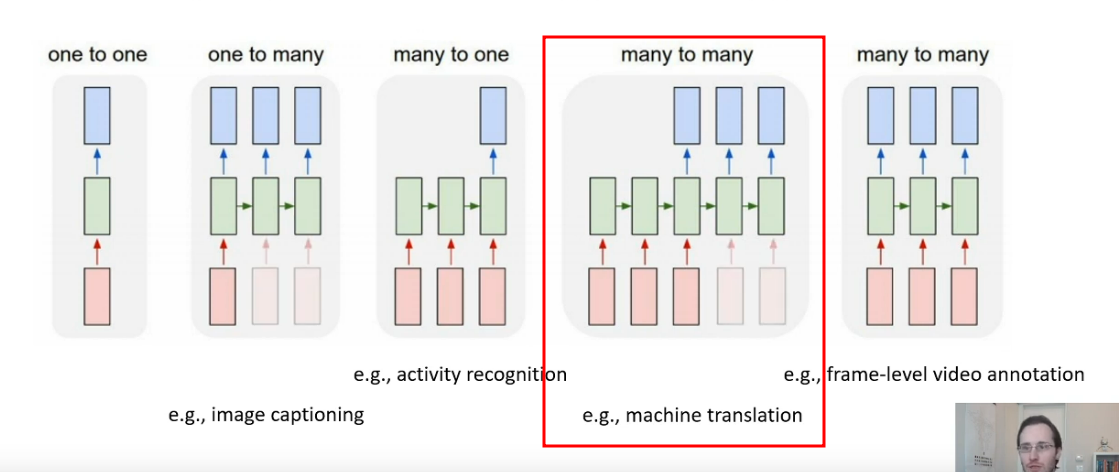
Can we do something further than just machine translation?
Generate text
Previous output will pass as input
But we need to process the encoder before generate text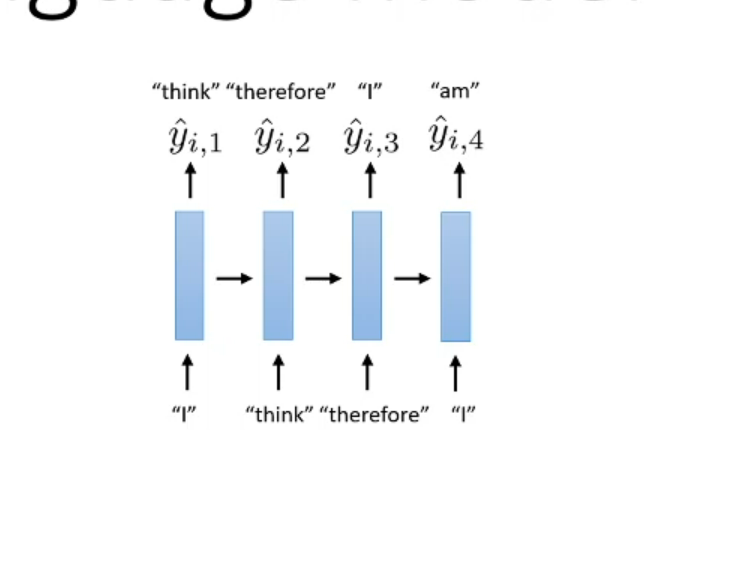
But how we represent the word?
There are many way. Simplest we can use one hot encoder
But more complex we use word embedding
How to know the generate word is end of sentence? each word need previous word but what about first word, what will be it’s input?
If we generate new whole sentence, the start token will probably random or some thing we pre define
We use token for start and end for separate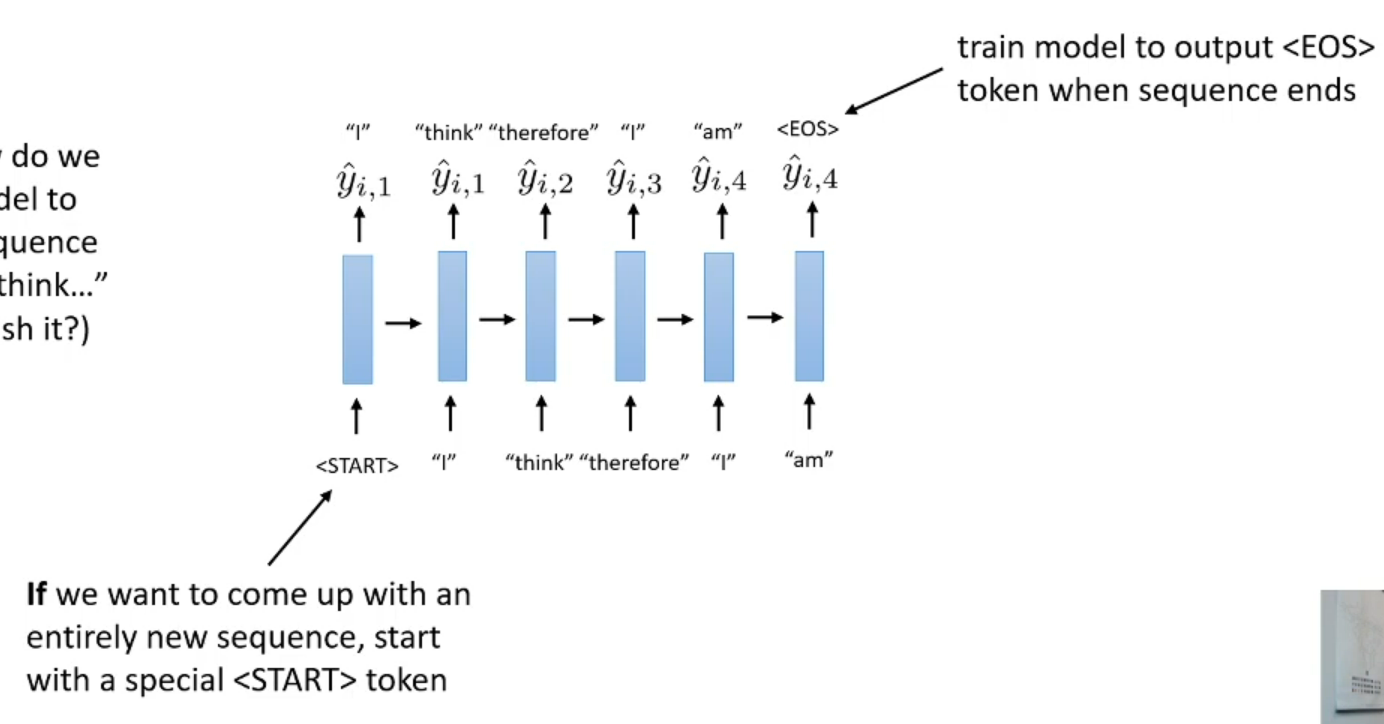
How to make language model learn predict the sentence (not same with how we run actual model)?
We feed the token on at the time => start predict but don’t sample from this prediction but direct feed the next word
How to predict the blank world in the sentence?
How to make image caption model?
CNN => Vector init state of RNN => Decoder to sequence
The result of CNN will we init vector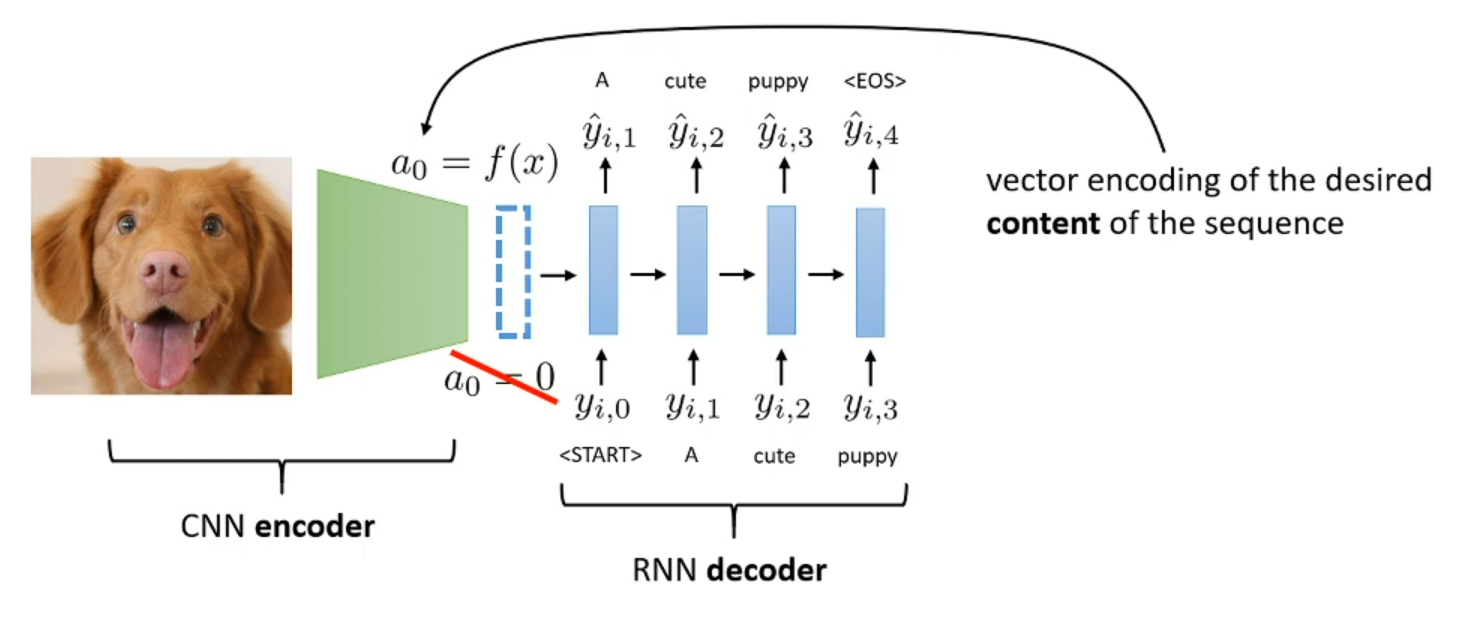
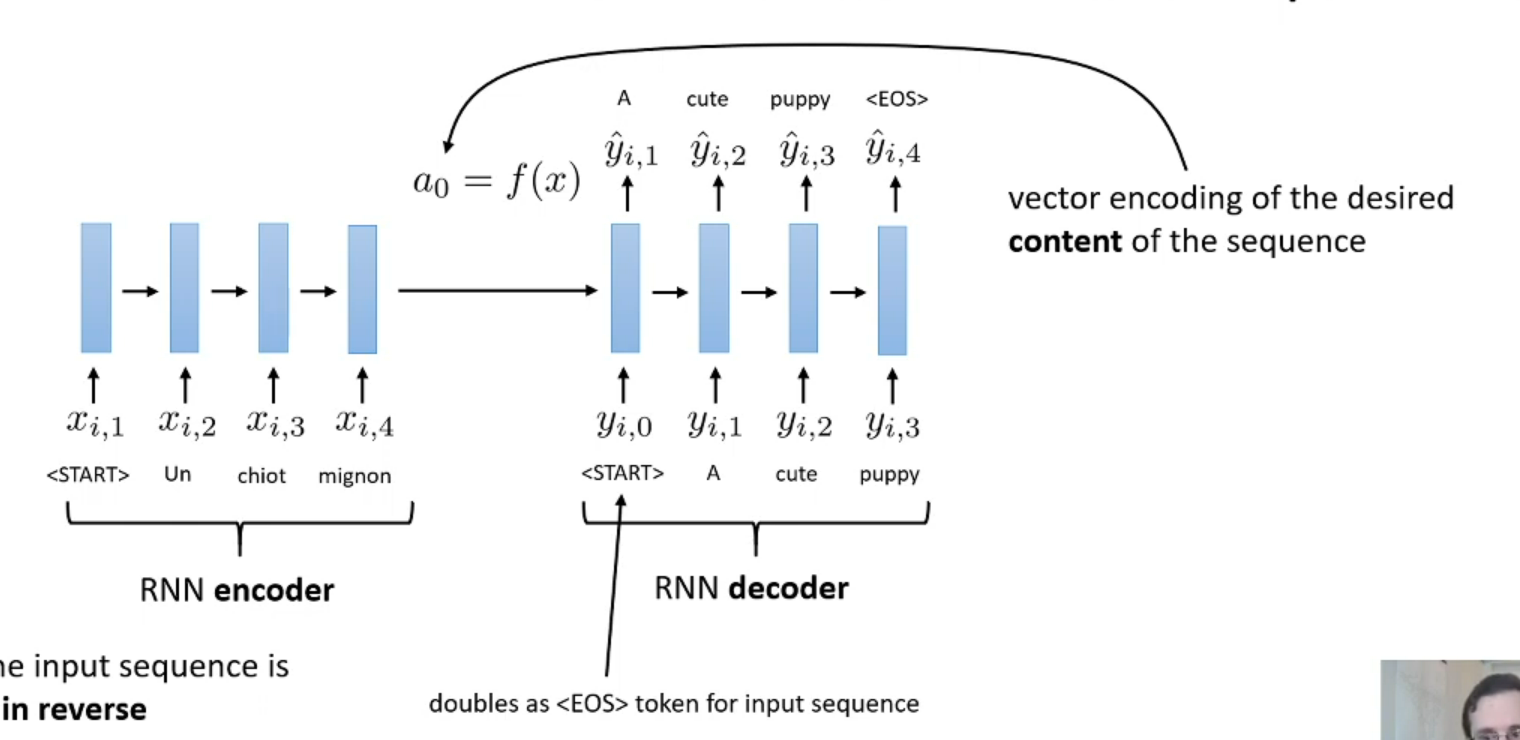
How to make the translate machine?
Another LSTM layer the produce the context information
How the trademark the start and end of sentence in both encoder and decoder of seq2seq?
The second <START> will be the start of first sentence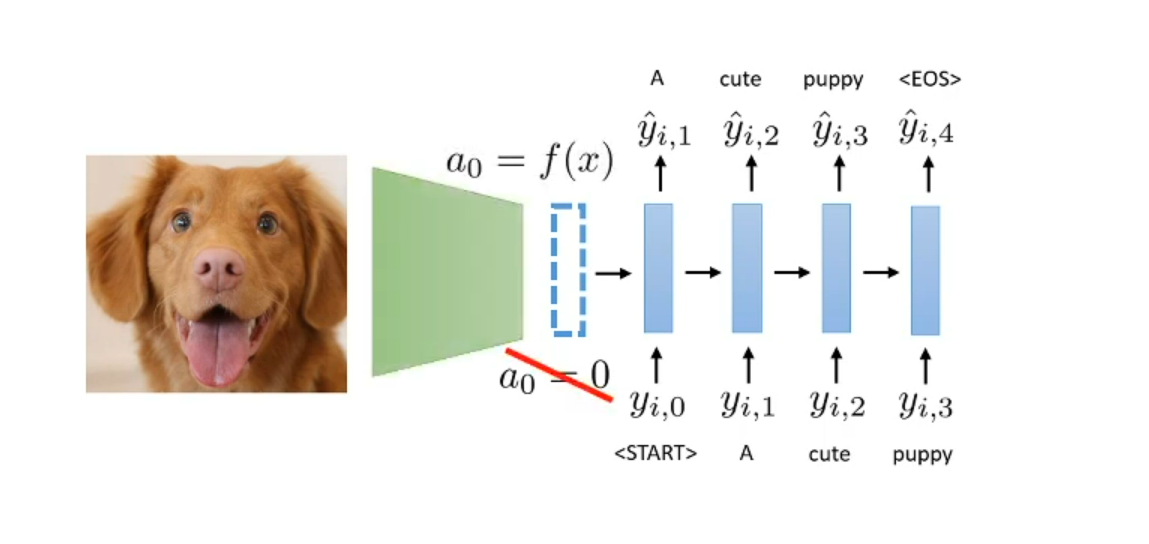
What we can use Seq2Seq for?
Beam search for seq2seq
Why we need beam search for machine translate?
For example if follow the greedy search we will overall get a point less sentence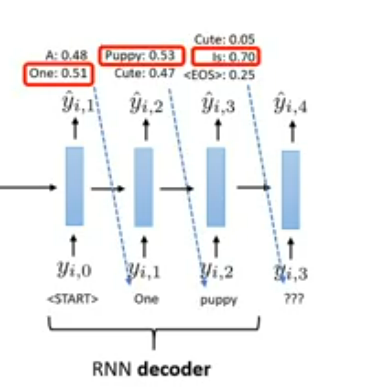
We want most probability for all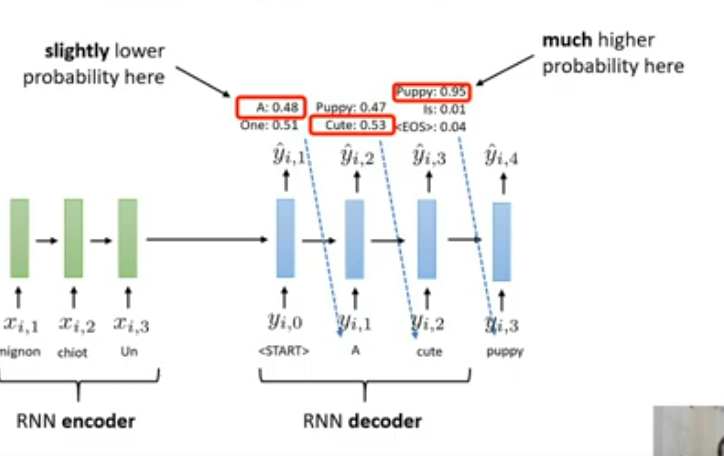
How to evaluate how goodness of a sequence we generate?
Each token will depend on the whole previous and the input sequence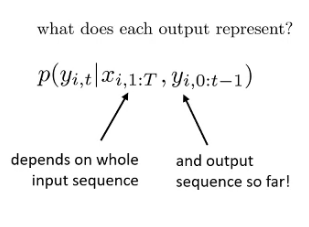
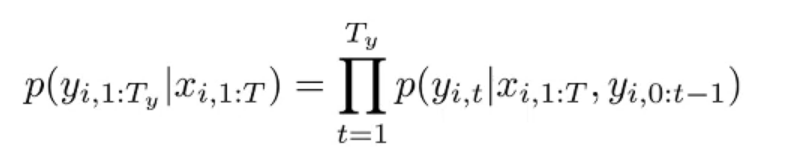
How large the possible different sequence can be?
Tree search => M word with length T will have $M^T$ (we can use graph search but not optimal)
But how to perform beam search sequence?
Search for k best word
Trick to better compute the goodness of sequence we generate?
Use log to compute sum instead of multiplication
=> Compute the log probability then choose the k from $k^2$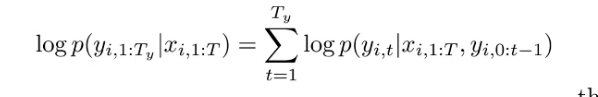
When we stop decoding?
Let’s say one of the highest-scoring hypotheses ends in <END>
Save it, along with its score, but do not pick it to expand further (there is nothing to expand)
Keep expanding the k remaining best hypotheses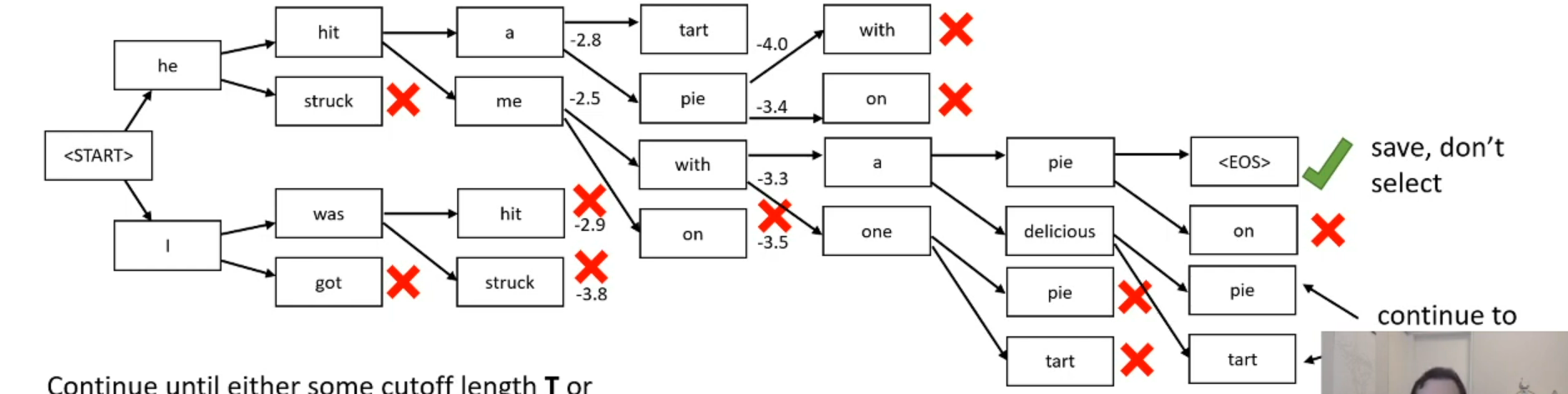
Continue until either some cutoff length T or
until we have N hypotheses that end in <EOS>
How to pick the sequence?
The longer the sequence the lower its total score (more negative numbers added together)
=> We can compute the average
Overall the process to perform beam search for generate the sequence?
Attention
What is the bottleneck problem of seq2seq?
All information decoder know is only the hidden state that encoder put to decoder
But it not work well in long sequence
Seq2seq like try to read the long sentence once and try to remember each word. What we most remember is the latest word but we need somehow to glimpse back to previous relate information to understand current sentence (attention)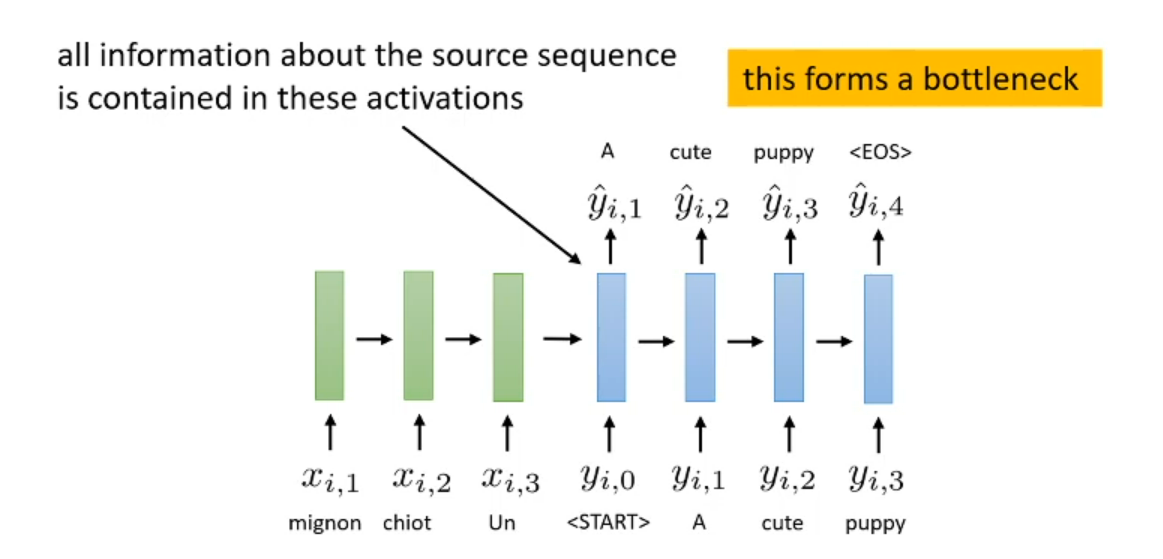
But what we want to perform better?
Idea: what if we could somehow “peek” at the source sentence while decoding
Can we look back for some important information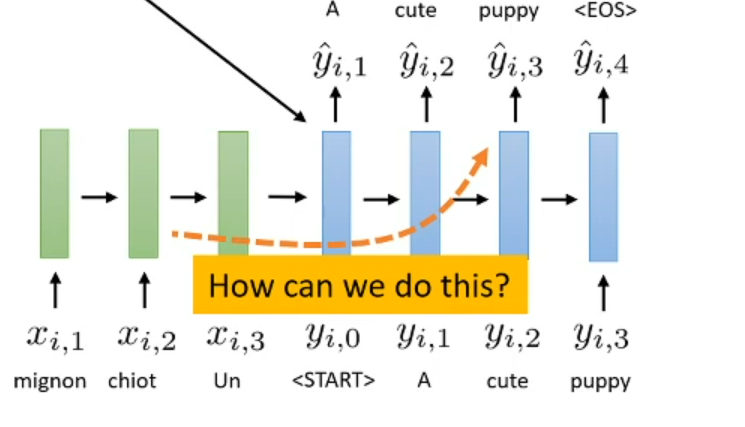
Let go for some terminology of attention
What is key?
The piece activation value in encoder (output of specific timestamp)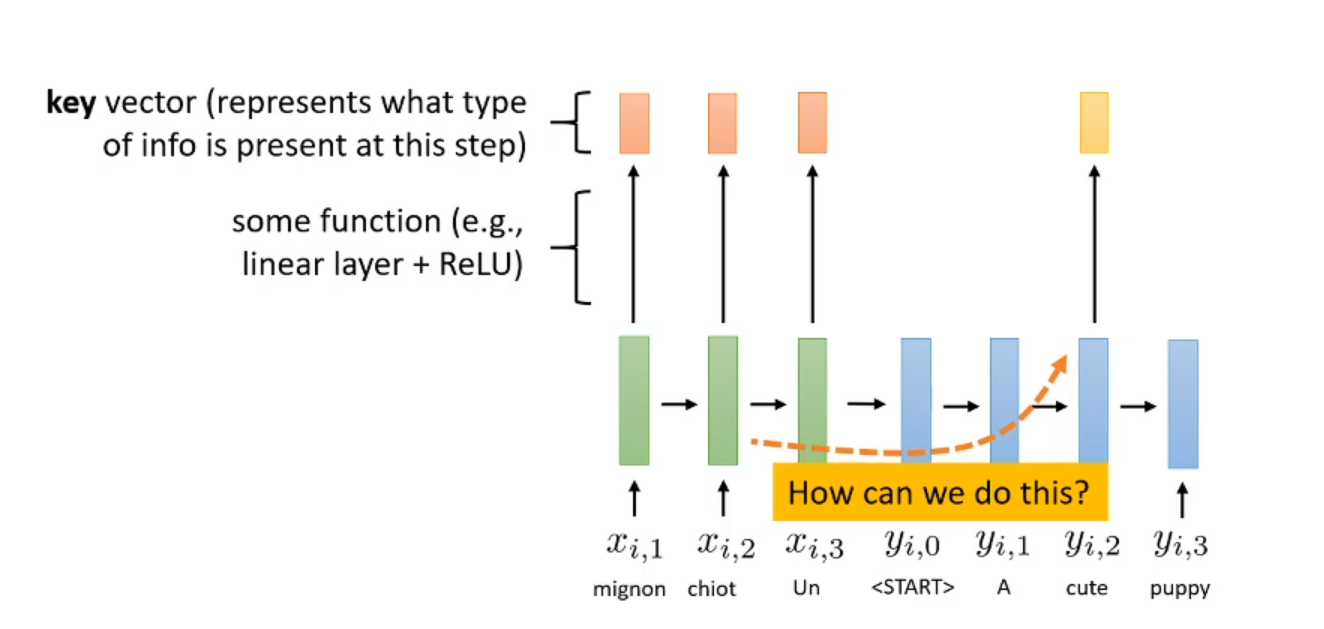
What is query?
Query represent what want want to looking for in encoder
=> We want to find what key that close to query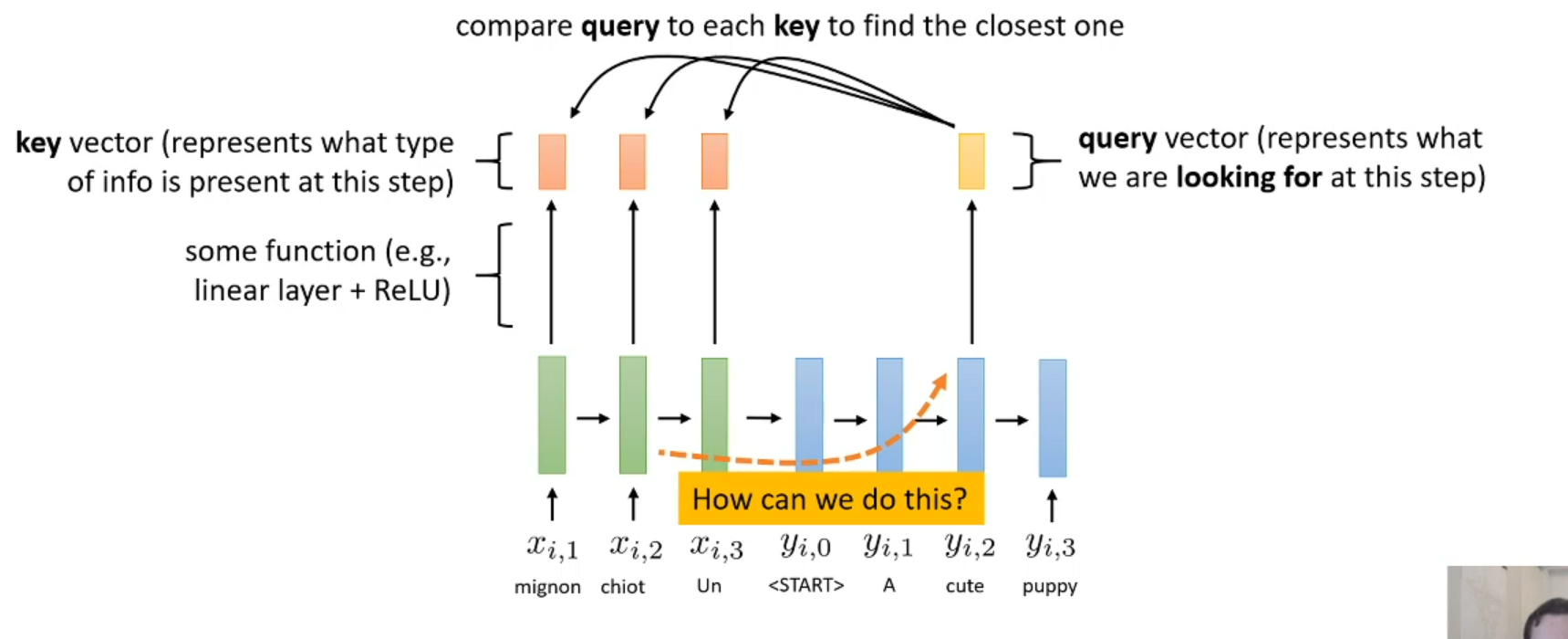
The point is keys and queries is learn by the neural system, we don’t need to manually specify it!
Why need have $h_t$ but not only the $x_t$?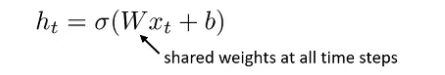
__
Share learn weight across the sequence like RNN
Represent the h for encoder and s for decoder and k for the key (is the result function in specific timestamp)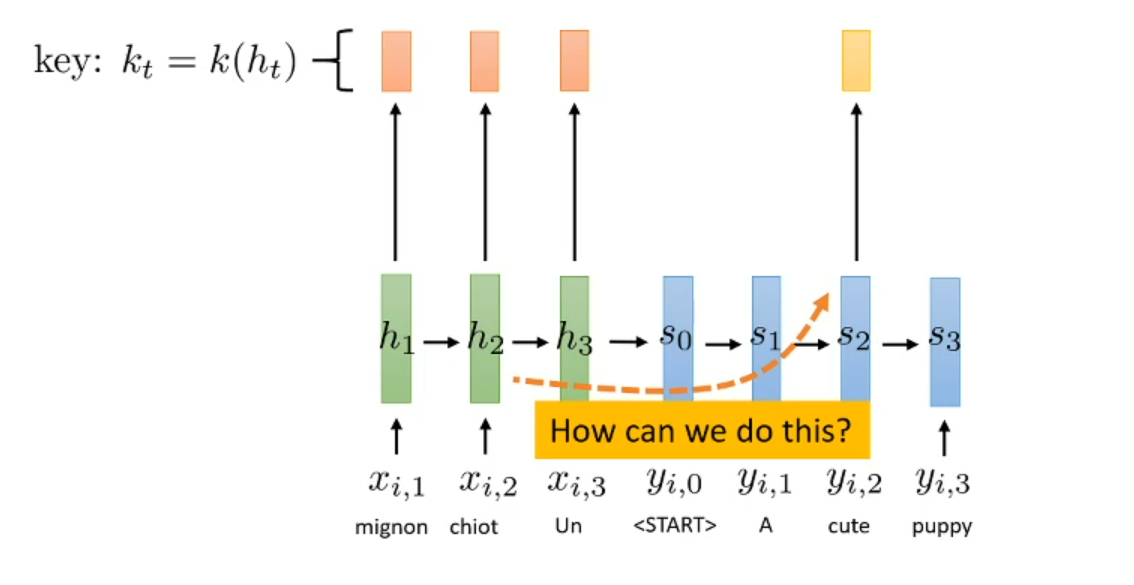
What is the relation of $k_t$ and $h_t$?
Let thing we apply the function k on specific timestamp
The k function could be something like linear function in $h_t$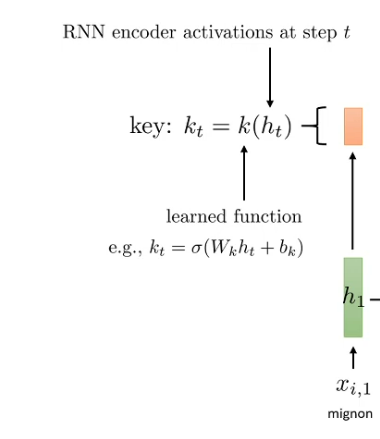
What is relation of $q_l$ and $s_l$?
Perform linear or non-linear q function on the specific $s_l$
How to evaluate the attention of query and value?
Perform dot product between $q_l$ and $k_t$
$e_{t,l}=q_l \cdot k_t$
The perform softmax on attention score
$\alpha_{t,l}=softmax(e_{t,l})$
Then with each timestamp in the encoder we half specific information $h_t$ correspond with the value $\alpha_{t,l}$
What we send to the current decoder is the sum with correlate value (we send the context vector)
How the decoder produce output base on result of attention?
The current activation value and the attention to produce the output $\hat{y}$ (not result of activation function)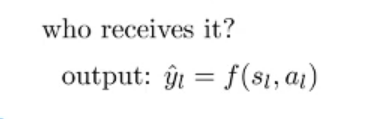
What will be pass to the next decoder step?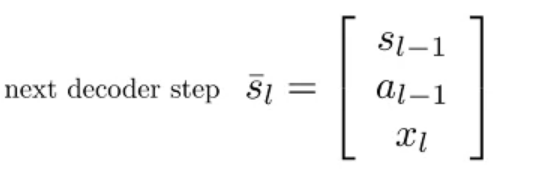
Quick overview the whole process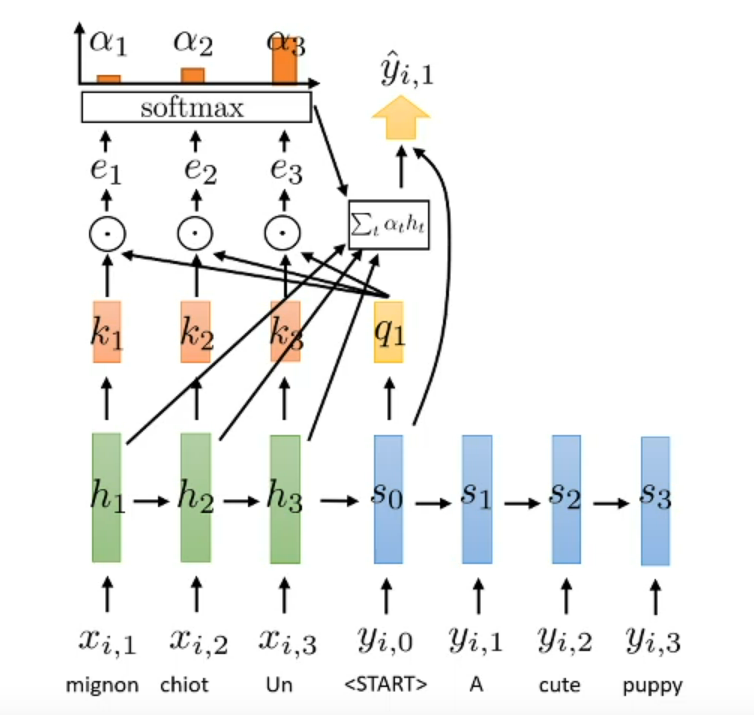
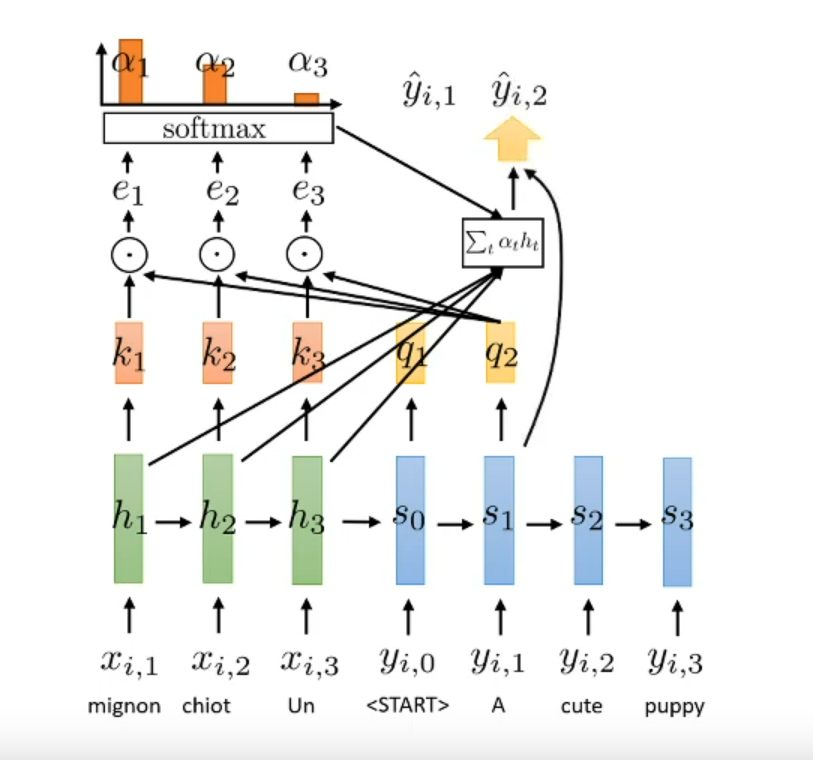
List all the way to use the context vector $a_l$?
Concatenate to the hidden state: it mean we will pass it into next timestamp
Use for readout: eg $\hat{y_l}=f(s_l, a_l)$ use to product output in a timestamp (if we have sequence of result)
Concatenate as input to next RNN layer: use to be input for next RNN timestamp
Attention variant for key and value choice?
- Simple => use direct the hidden state in encoder and decoder as key and value

- Linear multiplication attention: combine 2 linear weight will be a linear weight
(The W always learnable but keep in mind this is linear)
- Attention scale => perform some function v to change the scale of attention score
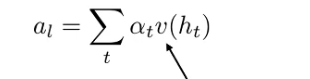
Why attention is good?
Decoder step can connect to all encoder step
Transformer
Can we use attention to replace the recurrent connection?
Yes, but attention allow us to access the previous input but how can we access to the previous output => self attention. Eg at s2 we want to access attention not only from encoder (h1-h3) but previous output s0 and s1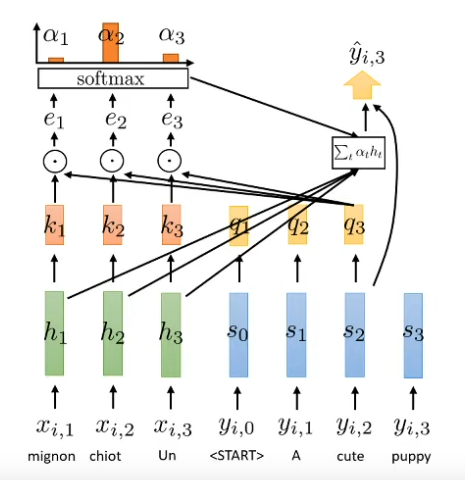
Feature use for the sequence model can be the image
Positional vector
What is purpose of positional vector?
Specify the position in when attention not use sequence for order element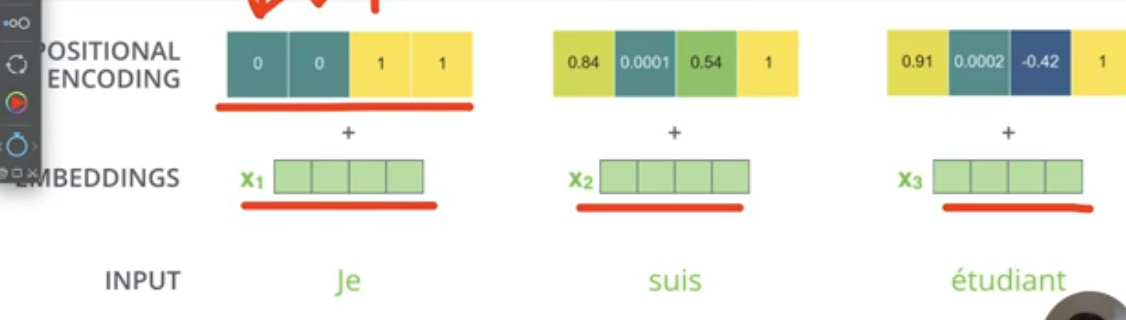
What is the dimension of positional vector and its value?
Same with the dimension of embedding vector
We use sin and cos for odd and even position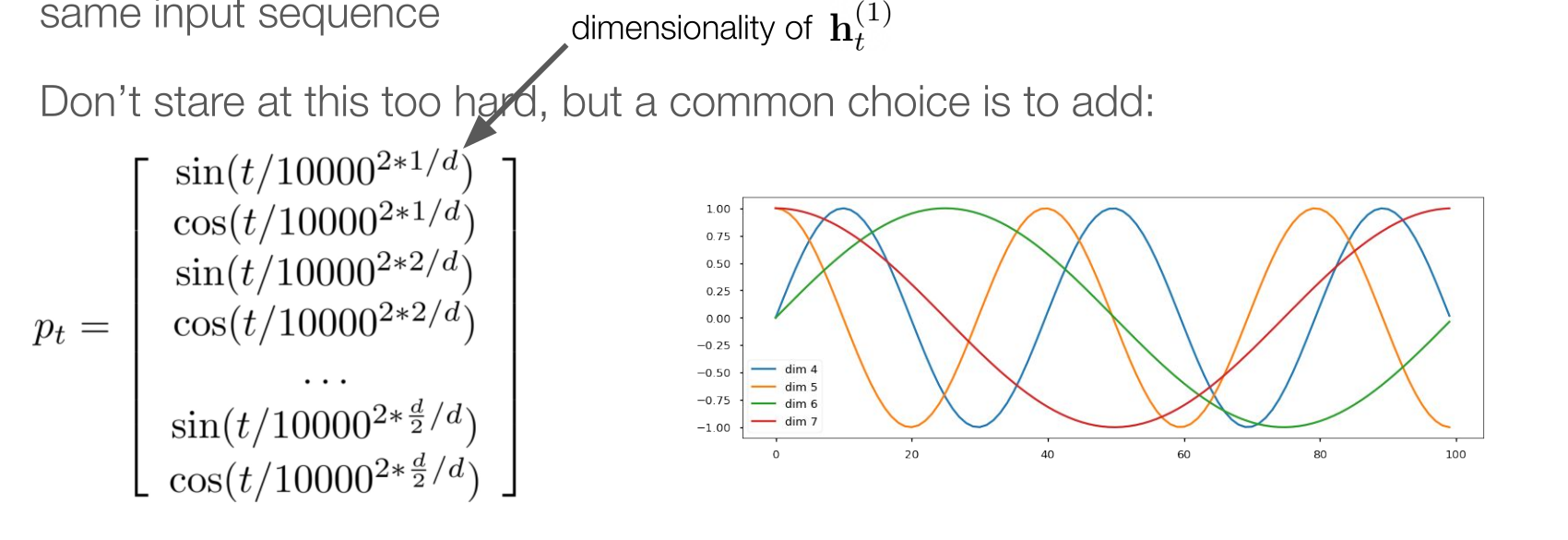
What is t in positional vector?
The time step in sequence
What is the range value of this?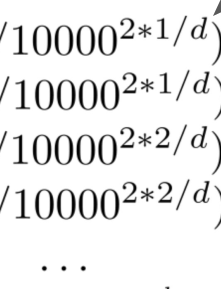
__
Increase according the value in the vector position and up to dimension
Why positional vector not use absolute position but a frequency represent (sin and cosin)?
Better to implicit the relative position
How to combine the embed vector with positional vector?
We often plus 2 matrix together

Self attention
Why we call it self attention?
Each word will compute the attention with every other word include itself to get the attention information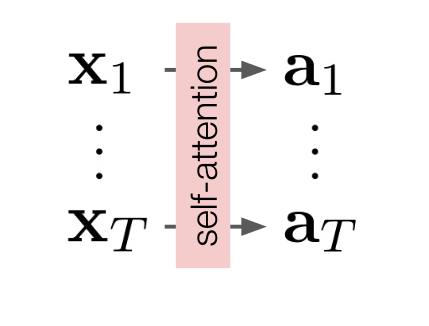

Attention? What it mean when 2 vector is relate each other?
Represent by the dot product of 2 vector

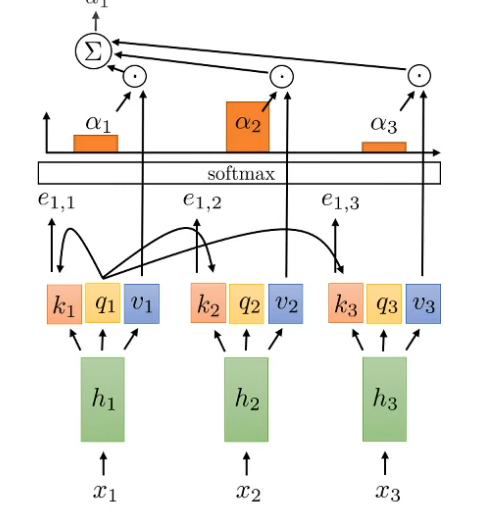
How to compute the attention over a specific time step?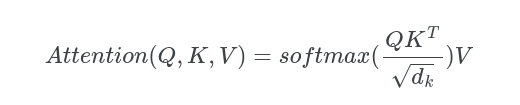
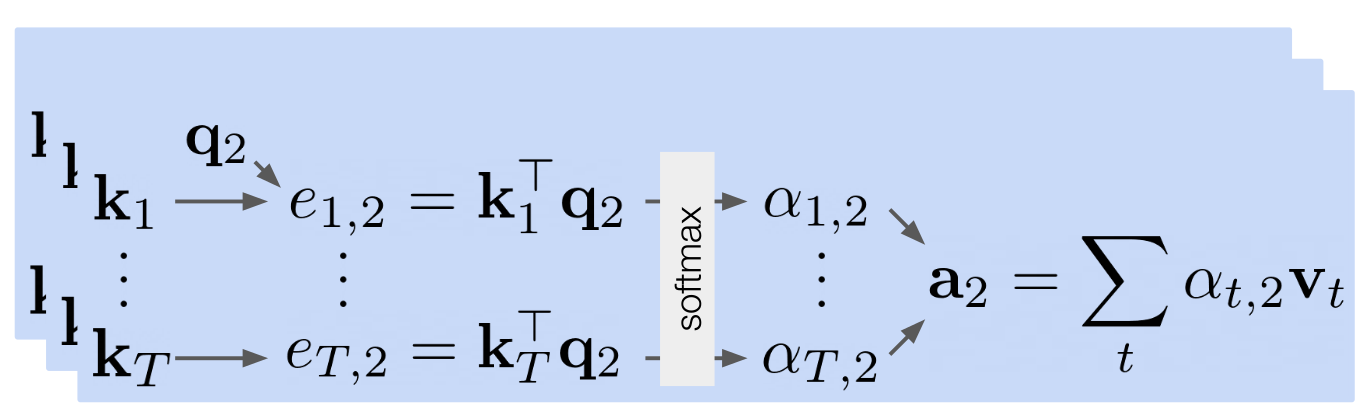
__
Key and query extract from input time step
For example we compute the attention for time step 2
We compute the relate of time step 2 over every other time step to get the softmax and multiply with the correlate value.
With d is the dimension of key vector. To avoid exploding value of attention in high dimension space eg 512 we need to divide by the dimension square
What the softmax multiply the value vector mean?
$v_t$ extract the value from input, with the softmax will represent the attention (in percent) of this information
The sum will represent mostly the information from argmax which mostly information we need to focus on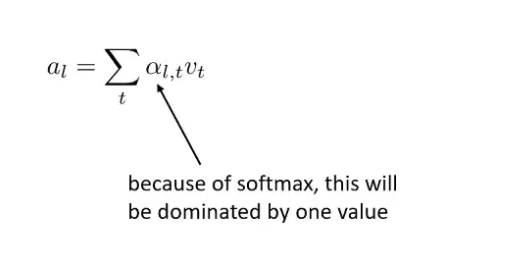
What is the dimension of keys, queries and and attention?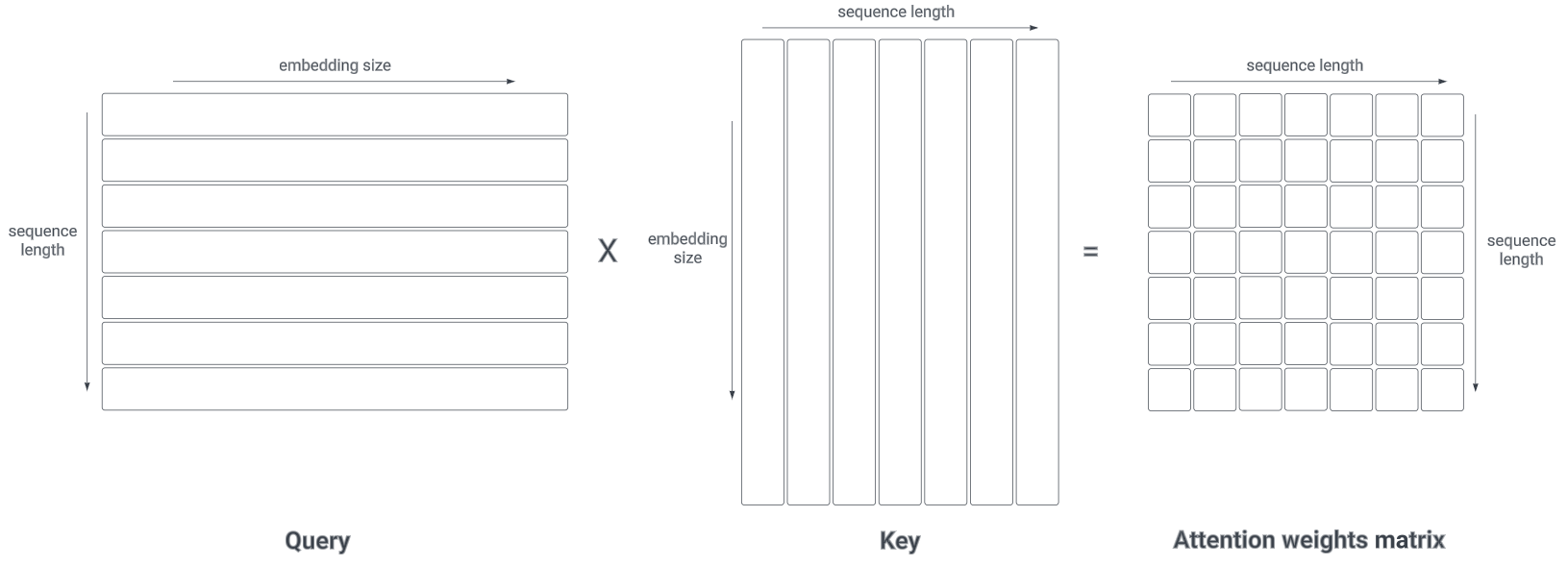
Why need masked attention?
Prevent attention lookup for future prediction which cause recurrent dependencies and attention information not able to converge
How to add more hidden layer like feed forward network but for self attention?
Pass attention information to next layer again and again
But in transformer we need to add nonlinear function before pass to next layer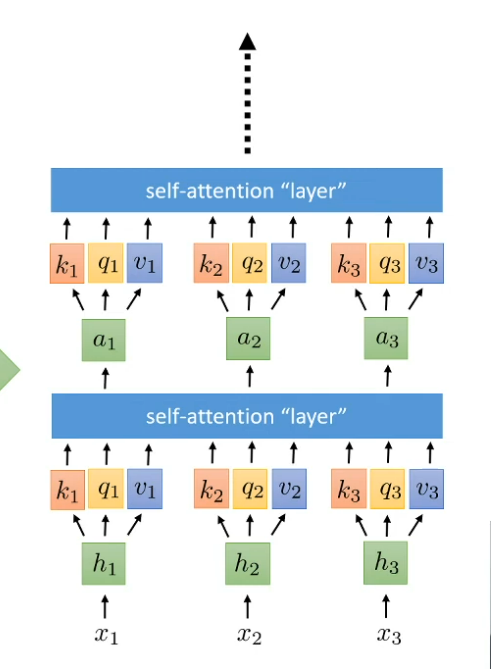
With self attention we allow to query for a specific information, how to query to many information and learn the relation of them?
__
We use multi head attention to query multiple position each layer
Eg: attention to query the subject and another for the verb
The output of self attention is linear or non linear?
Except the result of softmax but the sum over will be linear
The will be problem when we have many layer multi-headed attention connect to each other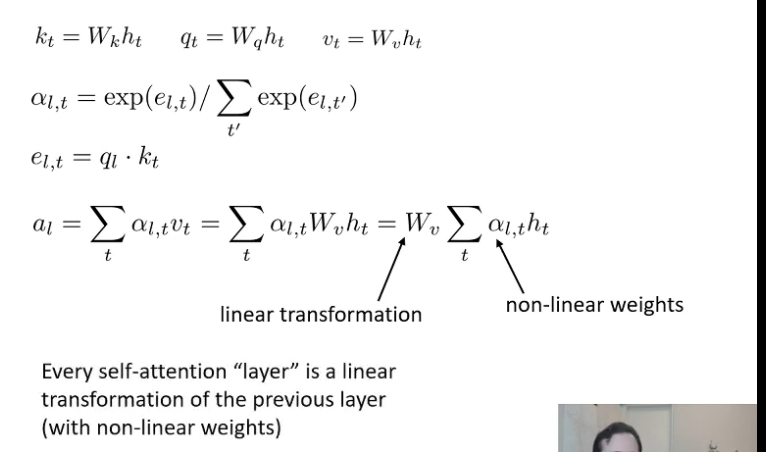
Multi-headed attention
What is multi-headed attention?
We have more than one self attention layer to learn the information we extract
We combine them together (concatenation) to have full attention vector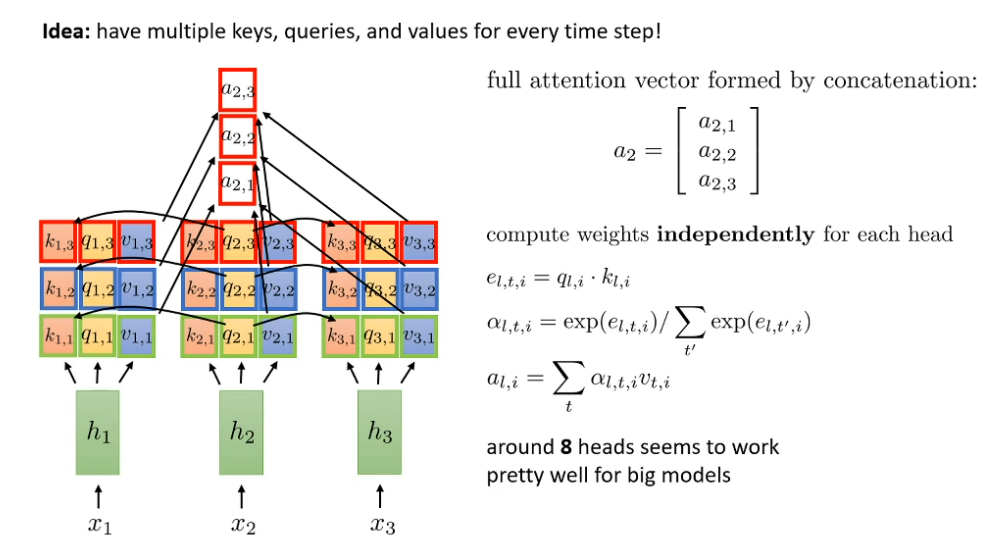
How to make result of each multi-headed attention (self-attention) to be non-linear?
Apply non-linear function for output result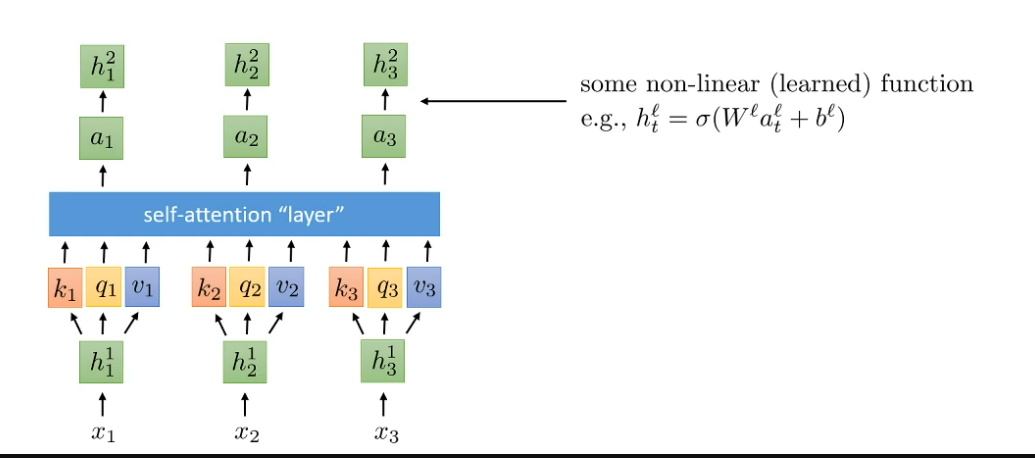
Masked encoding
How mask attention avoid lookup for future output to attention?
Assign the 0 value when in softmax computation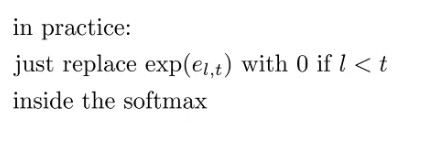
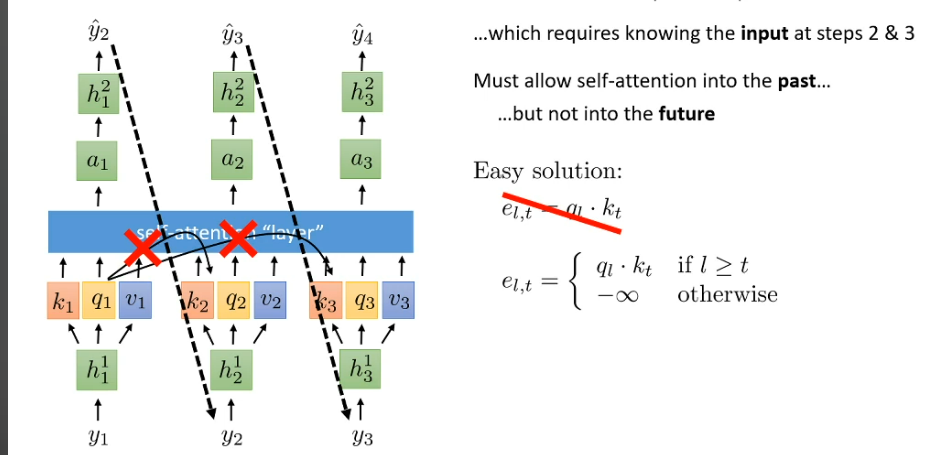
Classic transformer
Overall architect of transformer?
Use encoder compare input meaning
Decoder predict from input and previous output so far
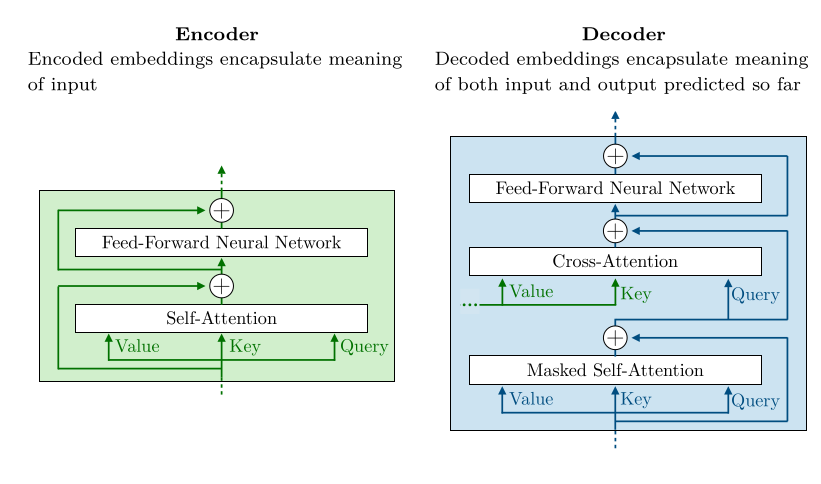
How encoder and decoder interact each other?
TODO: